
type
Post
status
Published
date
Mar 6, 2022
summary
利用K-均值聚类算法对未标注数据分组
slug
20220306
tags
深度学习
category
技术分享
password
URL
icon
无监督学习简介
无监督学习是一种机器学习的训练方式,它本质上是一个统计方法,在没有标签的数据里可以发现潜在的一些结构的一种训练方式。
无监督学习主要具备3个特点:
- 无监督学习没有明确的目的
- 无监督学习不需要给数据打标签
- 无监督学习无法量化效果
无监督学习的使用场景:
案例1:发现异常
有很多违法行为都需要”洗钱”,这些洗钱行为跟普通用户的行为是不一样的,到底哪里不一样?
如果通过人为去分析是一件成本很高很复杂的事情,我们可以通过这些行为的特征对用户进行分类,就更容易找到那些行为异常的用户,然后再深入分析他们的行为到底哪里不一样,是否属于违法洗钱的范畴。
通过无监督学习,我们可以快速把行为进行分类,虽然我们不知道这些分类意味着什么,但是通过这种分类,可以快速排出正常的用户,更有针对性的对异常行为进行深入分析。
案例2:用户细分
这个对于广告平台很有意义,我们不仅把用户按照性别、年龄、地理位置等维度进行用户细分,还可以通过用户行为对用户进行分类。
通过很多维度的用户细分,广告投放可以更有针对性,效果也会更好。
案例3:推荐系统
大家都听过”啤酒+尿不湿”的故事,这个故事就是根据用户的购买行为来推荐相关的商品的一个例子。
比如大家在淘宝、天猫、京东上逛的时候,总会根据你的浏览行为推荐一些相关的商品,有些商品就是无监督学习通过聚类来推荐出来的。系统会发现一些购买行为相似的用户,推荐这类用户最”喜欢”的商品。
K-均值聚类算法
核心思想
聚类是一种无监督的学习方法,它将相似的对象归到同一个簇中。K-均值聚类算法可以发现K个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。
簇识别:簇识别给出聚类结果的含义。假定有一些数据,现在将相似数据归到一起,簇识别会告诉我们这些簇到底都是什么。
工作流程:
- 随机确定k个初始点作为质心;
- 将数据集中的每个点分配到一个簇中(按照与质心的距离进行分配,每个簇中一个质心);
- 更新每个簇的质心为该簇中所有点的平均值;
- 重复2-3步直到数据点的簇分配节点不再发生改变;
代码实现:
二分K-均值算法
为了克服K-均值算法收敛于局部最小值的问题,有人提出了二分K-均值算法,该算法的核心思想如下:
算法首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否可以最大程度降低SSE(误差平方和)的值。不断重复上述划分过程直到得到用户指定的簇数目。因为对误差取了平方,因此更重视那些远离中心的点。
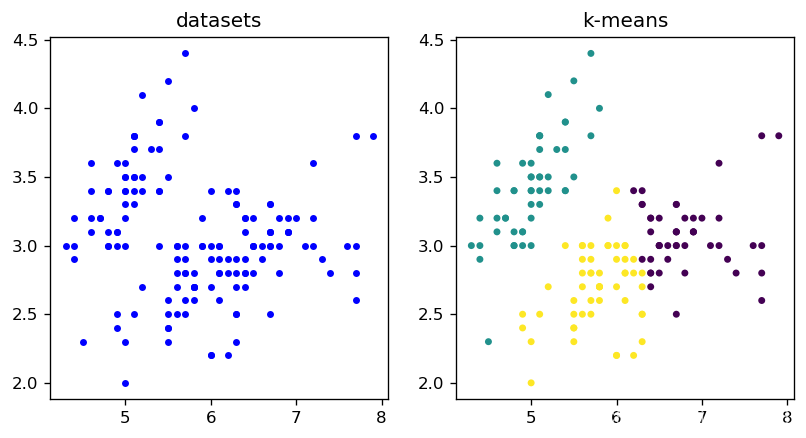
K-means聚类实战
鸢尾花分类
- 作者:luxinfeng
- 链接:https://www.luxinfeng.top/article/20220306
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。












